


In this article, we share how the Application Security (AppSec) team at Webflow successfully implemented a Software Composition Analysis (SCA) program. We’ll walk through the tools and processes we built, how we rolled them out, and the key insights we gained along the way.
Background
Software Composition Analysis (SCA) is a critical security control for managing vulnerabilities introduced through third-party software dependencies. While scanning codebases for known issues is foundational, a mature security program goes further, by operationalizing those findings and enabling teams to act on them efficiently and effectively. Incorporating SCA into a security program often presents significant challenges, including the overwhelming volume of alerts and false positives, inconsistent coverage across diverse tech stacks, and difficulty integrating seamlessly into existing Software Development Lifecycle (SDLC) pipelines, all of which can hinder timely remediation and reduce overall program effectiveness.
We wanted to shift left SCA to allow developers to receive timely, actionable feedback within their existing tools, reducing friction and response times. Shifting SCA left enables greater visibility, faster triage, and alignment with secure-by-design principles. It paves the way for a mature and proactive Application Security program that scales effectively across the organization.
One of the most valuable lessons we learned while implementing SCA was the importance of building a solution that aligned with both engineering needs and company culture. Flexibility was the key. For every control or process we proposed, we offered multiple implementation options and empowered teams to choose what worked best for them.
We also embraced an incremental rollout strategy. Every new initiative started small, targeting one to five teams, repositories, or Jira tickets. We gathered feedback, made adjustments, and only proceeded once we received 100% positive feedback. With that confidence, we gradually expanded the scope, onboarding additional teams, repositories, or issuing broader ticket coverage. Once we achieved full coverage for that phase, we repeated the same measured approach for the next step in the process.

SCA challenges
Implementing a Software Composition Analysis (SCA) solution brings significant benefits for securing software supply chains, but there are several challenges we had to face. Here are some examples:
- False positives and noise - Many SCA tools report vulnerabilities that are:
- Not actually exploitable (e.g., only in test/dev code).
- Already mitigated by application logic or configuration.
- This leads to alert fatigue, reducing developer engagement.
- Vulnerability context and prioritization
- Not all CVEs are equal. Without context (e.g., reachable code paths, in-use libraries), it’s hard to know what to fix first.
- Teams need help triaging real vs. theoretical risk.
- Version conflicts and fixability
- Even when a vulnerability has a fix, upgrading a library might break other parts of the system.
- Dependency complexity and tight coupling slow remediation.
- Developer adoption and workflow integration
- If the tool isn’t integrated into CI/CD or developer tools (e.g., GitHub, VS Code), adoption suffers.
- Manual processes for reviewing or suppressing issues create friction.
- License compliance issues
- Many teams focus on CVEs but overlook open-source license violations, which can introduce legal risk.
- Managing license policies (GPL, MIT, BSD, etc.) across dependencies is a separate layer of complexity.
- Inconsistent policies across teams
- Without centralized governance, each team may handle vulnerabilities differently, some patch immediately, others ignore or delay.
- Lack of standard SLOs, suppressions, or exception processes leads to inconsistent results.
In the following section, we walk through how we successfully implemented an SCA program at Webflow, overcoming the key challenges that came with it.



















We’re hiring!
We’re looking for product and engineering talent to join us on our mission to bring development superpowers to everyone.
Implementation steps
Step 0: Inventory - you can’t protect what you don't know
A fundamental starting point for any SCA program is establishing an accurate, continuously updated inventory of repositories. In a fast-moving engineering organization, engineers create and retire repositories regularly, so our SCA solution needed to adapt dynamically to these changes.
To identify which repositories should be covered by SCA, the AppSec team proposed three inventory approaches:
- GitHub topics: engineering teams tag their repositories with predefined topics (e.g.,
business-critical-yesorbusiness-critical-no) at creation time. - Metadata file: each repository maintains a
metadata.jsonfile containing fields like "enable SCA scanning", associated microservice, deployment info, etc. - External database: a centralized spreadsheet, jointly managed by engineering teams, listing all repositories with ownership and SCA-related metadata.
Engineering picked the GitHub topics option. Based on that, we automated this process with a bot that runs weekly and compiles three lists:
- All repos tagged
business-critical-yes- These repos are added to our SCA scanning tool if not already scanned.
- These repos are added to our SCA scanning tool if not already scanned.
- All repos tagged
business-critical-no- Those Repos are removed from the scanner.
- Those Repos are removed from the scanner.
- New repos with no business-critical topic and inferred ownership (via
CODEOWNERSfile or repo creator)- AppSec reaches out to the owners to have the appropriate topics assigned. We follow a "trust but verify" model, engineering teams are encouraged to tag repos at creation, and AppSec only steps in when tags are missing.
The automation consumes the metadata to also generate an inventory.json config file to be used during the SCA scanning process (More about the inventory.json in the next sections).
Step 0.1: Ownership - knowing who's responsible
Accurate ownership is essential for effective SCA, particularly when it comes to reporting and remediation. For most repos, ownership can be derived from the CODEOWNERS file or the original creator. However, in monorepos or shared codebases, ownership must be more granular, down to the level of specific third-party dependencies.
We proposed three options for capturing ownership:
- CODEOWNERS file
- Metadata file
- External source of truth (e.g., Google Sheets, Confluence, Renovate)
Our automation was designed to be agnostic to the source of ownership data. No matter which option a team selected, the script would parse and normalize the data before passing it to the reporting module.
By allowing engineering teams to choose the ownership mechanism that best suited their workflow, we significantly increased adoption and accuracy. In our case, the preferred approach was an open source tool called Renovate, that our Developer Productivity teams introduced for automated patching. Our scripts pull the Renovate data (renovate.json) via API to correlate package ownership before issuing any reports.
This flexibility helped establish stronger partnerships between AppSec and engineering, by solving problems together instead of enforcing rigid processes.
Step 1: Onboarding - scanning for vulnerable dependencies
While most modern SCA tools support the necessary API integrations to automate repo onboarding, scan execution, and results retrieval, we ensured our SCA scanner would also provide good value regarding:
- False positive rate and tuning capabilities
- Scan result quality
- Ease of integration and configuration
We built our automation layer to be vendor-agnostic, replacing the underlying scanner would simply require updating the API calls within our scripts. The SCA tool scans every new PR looking for dependencies being added to the codebase. On top of that, it also runs a daily full scan with the goal to catch new vulnerabilities that might have been disclosed after the dependency has been added to the codebase.
Step 2: Integration - bringing scan results into the software development lifecycle (SDLC)
Once repositories are onboarded and scanned regularly (daily full scans and at every PR for new dependencies), the next step is to integrate the results into the engineering workflow in a way that aligns with existing processes and minimizes friction.
At Webflow, engineering teams use Jira for work tracking, organizing items into epics, tasks, bugs, etc. To integrate SCA into their SDLC naturally, we designed our automation to generate findings as Jira tickets, formatted and categorized in a way that matches how teams already operate. The integration lambda will cover every single repo from the inventory.json and run at least one synchronization per month to ensure SCA scanner data and Jira tickets are consistent.
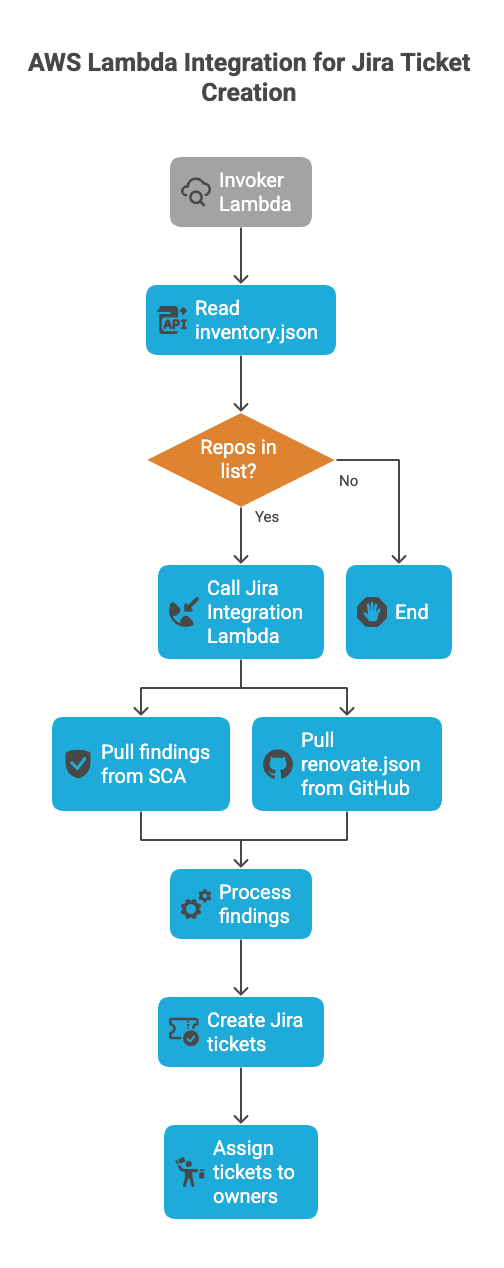
Rather than flooding teams with tickets immediately after onboarding a new repo, we take an incremental and controlled approach to avoid overwhelming them.
Dry run mode by default
When a repo is first onboarded to SCA, it enters a "dry run" mode according to the default config in the inventory.json file. During this phase, scans are executed, but instead of creating tickets, the results are compiled into an internal report. This gives the AppSec team a chance to:
- Review critical findings before escalating them.
- Weed out false positives.
- Adjust severity ratings if needed.
- Validate the signal-to-noise ratio before handing it off to engineering.
If we confirm any Critical issues, we notify the owning team and issue a ticket immediately. Otherwise, we queue findings for later triage or de-prioritize them accordingly.
Syncing with engineering teams
AppSec maintains monthly syncs with each engineering pillar. These touchpoints serve two purposes:
- Hear about upcoming changes on their roadmap (e.g., features needing security input).
- Share updates from AppSec, such as new tooling, initiatives, or findings.
We also discuss dry run findings during these meetings. Giving teams a heads-up allows them to plan ahead and allocate resources in upcoming sprints. When the repo is ready to exit dry-run mode, we enable ticket generation, starting only with Critical and High severity issues.

Once the high-priority backlog is under control, we gradually start surfacing Medium and Low severity findings, helping teams continuously improve without being buried in alerts from day one. We put the settings in place by customizing the inventory.jsonconfig file. The snippet below shows a “dry run” config for the Webflow monorepo that is run every second day of the month and only reports P0 and P1 findings (Critical and High).
Step 3: Automation - reporting findings at scale
At this stage, we’ve identified the repositories to scan, integrated our SCA software to scan them continuously, and established a review process for findings. Now, the challenge becomes: how do we efficiently report these findings across many teams, while maintaining centralized visibility and control?
The solution was to automate ticket creation in Jira, enriched with custom metadata using labels and custom fields. This allows us to both integrate with engineering teams’ workflows and maintain AppSec oversight.
Metadata-driven tickets
Our automation scripts parse the SCA scanner findings and create Jira tickets with metadata-driven fields. For example:
- A high-severity issue with a CVSS score of eight automatically gets tagged as
sec-sev-highand the due date is set according to the severity. - Tickets may also be tagged with the affected package name, repo name, and scan source.
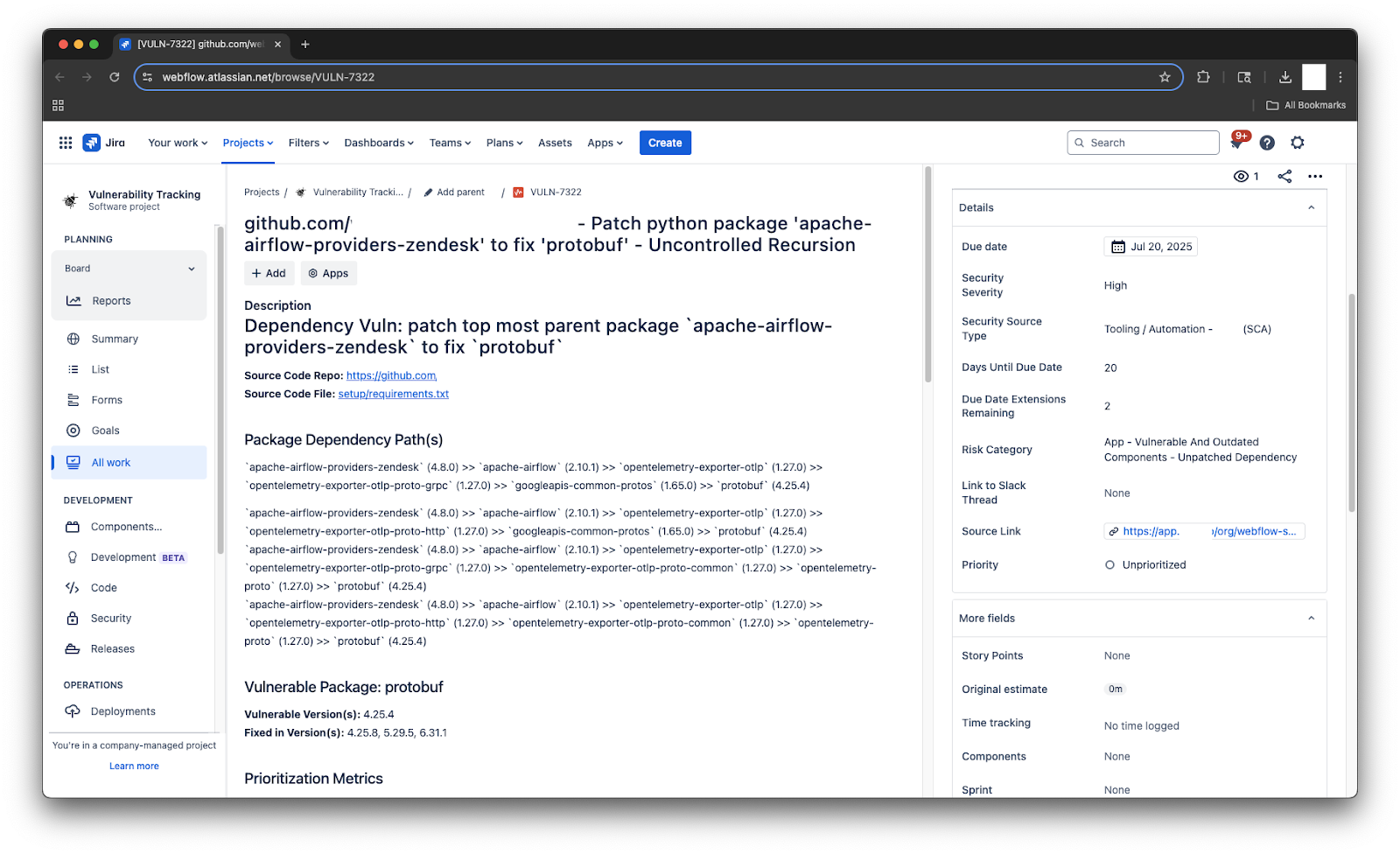
This structured tagging and custom fields allows AppSec to:
- Track vulnerability trends across teams or services.
- Build dashboards and heatmaps to visualize open issues by severity or location.
- Monitor remediation progress per team or per vulnerability class.
The AppSec team organizes its work in sprints. After each stand-up, we review Jira linters to track new vulnerabilities identified by SCA scanners, as well as monitor the status of issues already assigned to engineering teams. In addition to these linters, Jira dashboards provide a broader view of trends. If we spot anomalies, such as an unexpected increase in vulnerabilities, we proactively investigate the root cause and take action before the situation escalates.
Routing and workflow control
Instead of immediately assigning tickets to engineering teams’ Jira projects, we first create tickets for all new findings in an intermediary Jira project used for overall Vulnerability Management (eg: VULN jira project). This step allows for a manual review before pushing bulk tickets into a team’s SDLC.
This review helps ensure accuracy and relevance. For instance:
- A high-severity issue in a package used only by a service scheduled for deprecation might be downgraded.
- A finding could be flagged as a false positive or reclassified based on external business context unavailable to the scanner.
Once reviewed and approved, we move the ticket to the appropriate engineering team’s Jira project, based on metadata or routing rules.
Engineering autonomy
While AppSec owns and controls the security metadata, engineering teams retain full control over their SDLC-specific fields, such as priority, effort estimation, or sprint planning tags. This separation of concerns ensures alignment without stepping on team-specific processes.
This structured automation approach gives AppSec a central view of SCA vulnerabilities while seamlessly embedding remediation workflows into engineering pipelines.
While engineering teams vary, we found that the vast majority consistently resolved SCA findings within the AppSec SLA. This has enabled the AppSec team to bring critical findings down to zero and confidently project similar progress on high-severity issues within the next one or two quarters. For the few outliers unable to meet the SLA, we provide support through follow-up syncs, as detailed in the following sections.
Step 4: Corner cases - can we patch everything?
Most SCA workflows focus on severity, vulnerable versions, and remediation status, but real-world scenarios often introduce edge cases that don’t fit neatly into those categories. At Webflow, we built our program to handle these corner cases effectively, avoiding unnecessary friction with engineering teams while still maintaining a strong security posture.
Reachability: Not all criticals are equal
One key metadata field we leverage is reachability, whether the vulnerable code is actually invoked in the application.
A finding marked Critical by the SCA scanner would typically trigger a high-priority response, possibly even a security incident. But if reachability is marked as false, we treat it as a non-exploitable vulnerability. In that case, we may downgrade the severity to High, allowing it to remain urgent but avoiding disruption to team workflows.
This approach helps us balance risk with pragmatism, ensuring we focus incident-level urgency only on exploitable issues.
Third party licenses and end of life
Even if a third-party package has no known vulnerabilities, that doesn’t mean it’s automatically approved for use. To address this, the AppSec team collaborated with Webflow’s Legal team to define a standard for third-party library usage. Our automation also creates Jira tickets for packages that use unauthorized licenses, as well as those flagged by Renovate as end-of-life or unmaintained. This process enables the AppSec team to review these edge cases and partner with Engineering to ensure only approved third-party packages are adopted.
No fix available: don't spin wheels
Another important field is “Is fix available”. If a confirmed Critical vulnerability has no available fix, that’s an immediate concern. AppSec and the owning engineering team work together on mitigation strategies, such as replacing the dependency, implementing compensating controls, or isolating affected components.
However, if the issue is non-critical and unpatchable, it doesn’t make sense to create noise. These are tagged as sec-no-fix and tracked as inactive Jira tickets in the VULN project.
Our automation re-checks these findings regularly. If a patch becomes available, the script updates the ticket with the fix version and a sec-new-fix tag and reactivates it for review.
Linter-drive triage for late fixes
We also maintain Jira linters that monitor for tickets tagged with sec-new-fix. These represent previously unfixable vulnerabilities that now have a patch available, meaning the window of exposure is finally closable.
During AppSec sprint standups, we review these flagged tickets multiple times a week. Once verified, we triage and assign them immediately to the correct engineering team for remediation.
Why this matters
SCA tools will always surface edge cases. If not handled carefully, these can:
- Generate friction between AppSec and Eng Teams.
- Lead to unnecessary back-and-forth.
- Cause delays in remediation or weaken engagement.
SCA findings - corner case triaging


By combining smart process design with custom automation, we’ve created a system that accounts for these nuances, filtering out noise and ensuring only actionable findings make it to engineering.
Step 5: Supporting the eng team - be a partner, not a blocker
Once SCA findings are flowing into engineering teams' Jira pipelines through automation, the real work begins. A mature AppSec program doesn’t stop at ticket creation. Security isn’t just about identifying issues, it’s about enabling teams to fix them effectively.
Findings are the start, not the end
Expecting engineering teams to handle every vulnerability on their own is unrealistic. Even with good tooling and clear severity tags, real-world development introduces complexity:
- Upgrading a package may cause breaking changes.
- The vulnerable dependency might be scheduled for deprecation in an upcoming roadmap item.
- Fixing a vulnerability immediately might delay a larger refactor that would eliminate it entirely.
If AppSec wants to raise the security bar, it must be ready to engage beyond detection.
Shift the mindset: enable the mission
The AppSec mindset should be:
"We’re here to protect the company’s mission and its customers, not to patch everything blindly."
This means understanding the context behind each issue. Security must align with business and engineering goals, not disrupt them.
What support looks like in practice
AppSec teams should be prepared to:
- Collaborate on prioritization when a fix isn't feasible right away.
- Propose alternatives, like safer libraries, or recommend compensating controls (e.g., Web Application Firewalls, HTTP headers, etc.) to reduce risk while buying time.
- Contribute directly to the codebase by helping write PRs, or offering guidance on implementation challenges for shared packages.
Being willing to dive deep, whether that’s joining an engineering planning session or helping troubleshoot a failing build, transforms AppSec from a policy enforcer to a trusted partner.
Why it's worth the effort
Yes, this model adds more responsibility and pressure to the AppSec team. That’s why it’s so important to tune the earlier steps, especially filtering out noise, so that only the most meaningful and actionable vulnerabilities reach engineering.
But the payoff is huge: engineering teams will start to see AppSec not as a bottleneck, but as a valuable ally, a team that doesn’t just flag problems, but helps solve them.
Over time, this trust leads to stronger security culture, faster response times, and better adoption of secure development practices across the organization.
Step 6: Closing the loop – validating fixes and strengthening Webflow’s security posture
One more thing before we can call the SCA work done. We need to validate that reported issues were actually resolved, and use it to drive continuous improvement. This approach has strengthened the SCA program, reducing critical findings to zero and ensuring any new ones are addressed within days. It also sets the stage for achieving the same level of control over high and medium findings. We estimate this will be accomplished in the next 3 to 6 months.
Automated validation after ticket closure
A new validation ticket is automatically issued to AppSec once the original Engineering ticket is closed whenever the severity is high or critical. This ticket prompts the AppSec team to verify the fix, checking that the patch fully mitigates the reported vulnerability and that the repo’s next scan reflects a clean result.
Proactive monitoring of SLA and stale tickets
The same automation also tracks SCA tickets that are approaching or exceeding SLA thresholds, or are marked as open but show no recent activity.
Rather than letting these issues linger, we proactively surface them in our regular check-ins with engineering teams. The check-ins are performed monthly between AppSec and engineering team leadership. Among several routine topics in the agenda, we go over a Jira linter and discuss all tickets that need attention due to their due dates.
This final step ensures accountability and follow-through, preventing critical issues from falling through the cracks. Most importantly, it reinforces that SCA is not just a compliance checkbox, it’s a collaborative, continuous process that raises the organization’s security posture over time.
Conclusion: building a sustainable SCA program that engineers will actually use
Implementing a successful Software Composition Analysis (SCA) program is not about pushing tools into the pipeline and hoping for the best. It’s about building trust, creating flexibility, and embedding security into the way engineering teams already work.
At Webflow, we approached SCA not as a one-size-fits-all mandate, but as a collaborative effort. By designing processes that were incremental, customizable, and automation-friendly, we enabled security at scale, without disrupting developer velocity. Every step in the workflow, from repo inventory and ownership mapping, to ticket triage, validation, and follow-up, was crafted to reflect a single principle: security should be an enabler, not a blocker.
The payoff? Engineering teams are more responsive to security issues, more confident in the tools and processes we’ve built together, and more open to working with AppSec as a strategic partner. And that, more than any dashboard metric or vulnerability count, is what real AppSec maturity looks like.
If you're building or scaling your own SCA program, start with the people, then build the automation. Empower engineers with context and support. And always aim for meaningful, actionable findings, not noise.
Special thanks
This project succeeded thanks to the support and collaboration of many individuals and teams who not only helped build the solution, but also adopted it, provided feedback, and reported issues along the way. I’m especially grateful to the Webflow Engineering teams for embracing our SCA program and strengthening our security posture.
Special thanks to Topher Chung, Ankit Agrawal, Albert Chang, and Matias Altman for leveling up the SCA efforts at Webflow.