



After spending months updating pricing logic, we knew something had to change. This post walks through how we rebuilt Webflow’s billing infrastructure, giving teams the flexibility to ship updates without engineering bottlenecks.
Strategy pattern for zero-downtime rollouts
We implemented the Strategy Design Pattern across all our billing services to solve the gradual migration challenge. This pattern allowed us to maintain three different implementations of each service: a Stigg implementation for enrolled workspaces, a null no-op implementation for legacy workspaces, and a mock implementation for testing.
export function getEntitlementService(
opts: ServiceFactoryOptions
): EntitlementServiceInterface {
const loggerInstance = opts.logger ?? createDefaultLogger();
const eventEmitterInstance = opts.eventEmitter ?? getEventEmitter();
switch (serviceResolver(opts)) {
case SERVICE_PROVIDERS.MOCK:
return getTestingMockForService(StiggEntitlementService);
case SERVICE_PROVIDERS.NULL:
return new NullEntitlementService({
logger: loggerInstance,
eventEmitter: eventEmitterInstance,
});
case SERVICE_PROVIDERS.STIGG:
return new StiggEntitlementService({
logger: loggerInstance,
eventEmitter: eventEmitterInstance,
stigg: getConfiguredStiggClient(loggerInstance),
});
default:
throw new Error('Unknown service type');
}
}The best part of this approach was that calling code remained oblivious to which strategy it was using — it calls the same interface and receives consistent behavior whether it's hitting Stigg's live API, a no-op implementation, or mock data:
const strategy = await getBillingServiceStrategy(workspaceId);
const service = EntitlementService(strategy);
const entitlement = await service.getBooleanEntitlement({
workspaceId,
featureId: CAN_LOCALIZE_CMS,
siteId,
});
if (entitlement.hasAccess) {
// has access to localize CMS
}Each strategy implementation served a specific purpose. Our Stigg strategy handled the full integration with their API, including data transformation between their format and ours:
class StiggEntitlementService {
async getBooleanEntitlement(params: GetBooleanEntitlement) {
const entitlement = await this.stiggClient.getBooleanEntitlement(params);
const transformed = stiggToWebflowEntitlementTransformer(entitlement);
this.eventEmitter.emit('entitlement.get-boolean', transformed);
return transformed;
}
}Our null strategy provided a safe no-op implementation that preserved monitoring capabilities:
class NullEntitlementService {
async getBooleanEntitlement(params: GetBooleanEntitlement) {
this.eventEmitter.emit('entitlement.get-boolean', params);
return {};
}
}This pattern was essential for our migration success. It enabled zero-downtime rollouts, gradual workspace migration, comprehensive testing with mocks, and the flexibility to swap billing providers in the future by simply implementing new strategies.
Keeping two systems in sync
The strategy pattern solved our code organization challenge. However, we still faced a coordination problem: ensuring that workspaces enrolled in our feature flag rollout were properly enrolled on Stigg's platform. This synchronization was key for maintaining data consistency as we handed over subscription management from our legacy system to Stigg.
The core challenge was that we had two independent systems making enrollment decisions. Our feature flag system determined which workspaces should use the new billing infrastructure, while Stigg needed to know which customers it should actively manage. A mismatch between these systems could result in billing inconsistencies or service disruptions.
We solved this with an enrollment synchronization function that runs whenever a workspace interacts with our billing system:
export async function isStiggBillingSyncEnabled(
workspace: Workspace
): Promise<boolean> {
try {
return await getAndSetRolloutValue(workspace);
} catch (err: Error) {
if (shouldRunCustomerBackfill(err.message)) {
try {
await backfillMissingCustomer(String(workspace._id), err.message);
return await getAndSetRolloutValue(workspace);
} catch (backfillError: BackfillError) {
logger.error('Error backfilling Stigg customer', err);
}
}
return false;
}
}
async function getAndSetRolloutValue(workspace: Workspace) {
const isEnrolled = featureConfig.getFeatureFlag(FEATURE_FLAG);
await ensureEnrolledInStigg(workspace, isEnrolled);
return isEnrolled;
}This function became our source of truth reconciliation. It detected mismatches between our feature flags and Stigg's enrollment state, corrected them automatically, and cached the results to minimize performance impact.
Performance and reliability
The new billing system delivered notable performance improvements across the entire platform.
- By eliminating the synchronous Stripe API calls that previously blocked every plan change, we achieved a 95% reduction in sync operations for workspaces with large numbers of sites. This architectural change removed a notable bottleneck that caused timeouts and degraded user experience.
- In our entitlement system, we replaced a static capabilities config with dynamic, cached entitlement checks that provided centralized usage tracking—something we never had before. Previously, different features implemented their tracking methods (or didn't track usage), creating inconsistencies and performance overhead. The new system improved page load times while reducing code complexity across the platform.
- The caching strategy we implemented eliminated redundant API calls, automatically detected and corrected data inconsistencies, and ensured the system remained functional even during external service outages. This resilience was key during the migration period when we needed to maintain service reliability while coordinating between multiple systems.
- We developed distinct error-handling strategies based on the criticality of each operation. We classified enrollment failures as critical to prevent billing inconsistencies, and logged less critical operations without interfering with user workflows. Additionally, we implemented comprehensive backfill logic to address edge cases such as workspace restores, site clones, and temporary system failures.
Throughout the rollout, we monitored performance closely with dedicated DataDog dashboards that tracked cache hit rates, API response times, synchronization failures, and enrollment mismatches in real-time. This monitoring proved invaluable for identifying and resolving issues before they could impact customers and gave us confidence to accelerate the rollout timeline.
Reflections on the migration
The migration to the new billing system has transformed how we handle pricing and packaging changes. What once took months of engineering effort has become a non-event, with product managers now able to update plans and entitlements with little to no engineering involvement. This shift has empowered teams to implement changes quickly and confidently.
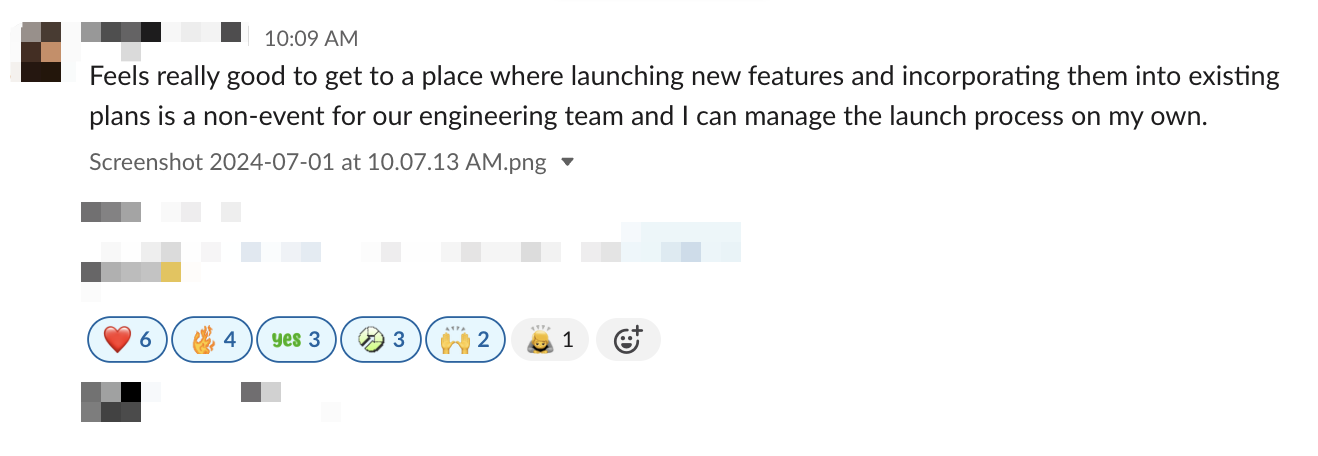
The strategic design decisions and comprehensive documentation have also enabled feature teams to add new features and entitlements with minimal Subscriptions & Payments team guidance. While we continue to clean up the remaining sections of the legacy system, this has laid a strong foundation for future growth and innovation at Webflow.
Lessons learned
Migrating a key system like billing taught us valuable lessons that will inform future large-scale migrations:
- Map all edge cases early, especially cross-system workflows. We missed accounting for site workflows like restores, snapshot reverts, and workspace transfers. These overlooked scenarios led to subscription discrepancies that required backfilling. We systematically catalog all workflows that touch the migration system before starting implementation.
- Plan for rate limits and external API constraints from day one. Due to workspaces with numerous sites, we faced rate-limit constraints from Stigg's API, leading to service disruptions. We worked with Stigg to increase limits and leverage an edge API backed by DynamoDB to reduce dependency on real-time external queries and provide better resilience.
- Legacy cleanup is more complex than the initial migration. While the new system worked beautifully, removing legacy implementations proved more complicated than anticipated. Coordinating with feature teams to migrate to entitlements while avoiding performance degradation required careful sequencing and extensive testing. We learned to allocate more time for cleanup phases in future migrations.
- Monitoring and observability are migration accelerators. Our comprehensive DataDog dashboards didn't just help us catch issues — they gave us the confidence to move faster. Real-time visibility into cache hit rates, API response times, and system health allowed us to accelerate rollout timelines because we could identify and resolve problems before they impacted customers.
Conclusion
Rebuilding our billing infrastructure was a complex but necessary endeavor to support Webflow's next decade of growth. This gave us a scalable and flexible foundation that reduces the engineering effort required to manage pricing and packaging changes while better supporting our future growth and customer expectations.
Among the key gains from this migration, we've dramatically improved the efficiency of our billing updates, allowing changes that once took months to be made in a fraction of the time. The new system enables us to introduce new features and pricing models without the heavy lifting previously required. It has been designed with scalability in mind, ready to support Webflow's expanding user base without becoming a bottleneck. We've achieved notable latency improvements — eliminating the synchronous API calls that previously caused timeouts and delivering faster, more reliable billing operations across the platform. Another important outcome of this project has been the decision to encapsulate third-party tools behind an internal service layer. This pattern simplified the current rollout and ensured that we could swap out third-party providers in the future without requiring notable changes across our codebase.
Looking ahead, there's still a lot to build. We've laid the foundation, but many of the most challenging and rewarding problems in billing, entitlements, and monetization are still ahead of us. If solving these kinds of challenges excites you, we'd love to hear from you—check out our open roles.



















We’re hiring!
We’re looking for product and engineering talent to join us on our mission to bring development superpowers to everyone.