


You probably know reCAPTCHAs as the gatekeepers to the internet — mini tests in the form of checkboxes, words, or photos that range from slightly annoying to comically frustrating.
But what is a reCAPTCHA, exactly? A reCAPTCHA is a service from Google designed to help protect websites from spam and abuse.
The original CAPTCHA test designed by a team at Carnegie Mellon University asked users to decipher numbers or letters. CAPTCHA is an acronym for Completely Automated Public Turing test to tell Computers and Humans Apart. Google redesigned the CAPTCHA test, improving its ability to keep out advanced bots and malicious software, and that new service is called reCAPTCHA.
Basic Google reCAPTCHA is a free service, but reCAPTCHA Enterprise allows you to extend the advanced risk analysis functionality across entire websites rather than being limited to certain pages.
All of these tests are meant to be easy for humans and difficult for bots so that only real people can access a website. At first, that was their sole purpose — to limit spam and bot activity on webpages. But reCAPTCHAs have come to play important roles in both book preservation and meme culture as well.
reCAPTCHAs helped digitize millions of words
Guatemalan computer scientist Luis von Ahn led the team behind the CAPTCHA project at Carnegie Mellon University. While the project’s original goal was to prevent automated services from abusing the web, the team realized there was potential to channel the human effort to simultaneously support another goal: digitizing old printed materials.
Printed materials with faded ink or yellowed pages, along with handwritten texts, are difficult to scan — optical character recognition (OCR) programs only recognize about 20% of the words.
Luis and his team estimated that humans spent hundreds of thousands of hours per day solving reCAPTCHA challenges. Rather than waste that work, the team fed words from scanned texts into reCAPTCHAs, essentially asking people to transcribe the texts word by word.

The New York Times (NYT) archives were ideal for testing because articles dated back to the mid-1800s, allowing the team to test scanned articles from five different years (1860, 1865, 1908, 1935, and 1970). Unrecognizable words were sent to multiple users to verify the transcription, resulting in a 99.1% accuracy rate.
After the successful experiment, the entire NYT archives were fed into the reCAPTCHA service. Within one year, internet users had transcribed more than 440 million words — the equivalent of 17,600 books.
By 2011, people solving reCAPTCHAs had unknowingly helped complete the digitization of the entire NYT archives. At this point, Google pivoted the project to support their massive effort to digitize basically every book in existence. While the official number of books digitized by reCAPTCHA verification is unknown, this effort combined with manual and artificial intelligence-supported processes accounts for millions of digitized books — 25 million of which Google is not allowed to share, but that’s a story for another day.
But not all reCAPTCHA efforts preserve historical articles and books
Even though using reCAPTCHAs to digitize old printed materials is incredibly cool for historical reasons, not everyone is thrilled about how far the project reaches. It’s one thing to help digitize NYT articles from the 1800s, but transcribing books for Google and feeding into their user interaction and behavior data is a different story.
Google has been criticized and even sued for using reCAPTCHAs to facilitate unpaid transcription labor that Google ultimately profited from. While internet users continued to transcribe books, documents, and articles from various universities and governments for free, Google was charging for the service.
Things got even murkier when photo reCAPTCHAs hit the internet in 2012. Images and numbers pulled from Google Street View pop up in reCAPTCHAs, asking users to verify the street names or address, which provides Google with image recognition data they need to improve Google Maps.
These days, you might not see many street address prompts, but it’s not because Google is done collecting data. Now, Google performs a behavioral analysis of browser interactions to try to guess if users are human. If the actions seem human, Google serves up the no CAPTCHA reCAPTCHA, which is a simple checkbox that asks you to confirm you’re not a robot. Web developers can also use invisible reCAPTCHAs, which skip the checkbox and verify the user when they click on an existing button or via a JavaScript API call.
If you aren’t deemed human by one of those methods, you’ll probably get the “select all squares that contain” version of reCAPTCHA. These tests ask you to look at a photo separated into a grid and select only the squares containing a certain object, such as a traffic light or car.
We may not love everything about reCAPTCHAs, but I’d argue there is one major benefit of Google’s shift to more photo grids — the spawning of several new meme formats.
reCAPTCHAs earned their spot in meme history
If you give the people of the internet out-of-context photos or words, memes are pretty inevitable. Strange word pairings, dreary street photos taken at awkward angles, and frustrating authentication failures quickly turned into internet jokes.
The original CAPTCHA earned confirmed meme status in 2000. Back then, most related memes were CAPTCHArt — a format that involved “drawing comics or photoshopping images inspired by a word pair randomly generated by CAPTCHA.”
For example, a drawing of someone struggling after being asked to type the word pairing “don’t type” or the Dawson Crying meme combined with the pairing “teardrop 35c.”

Text CAPTCHAs also fueled Inglip memes, but this style goes deep into the depths of internet culture. Inglip is “an internet folklore based on the eponymous rage comic character who can communicate with mythical acolytes known as Gropagas through the medium of CAPTCHA images.”
Basically, a scribbly internet dude thinks CAPTCHAs are messages from a mythical being.
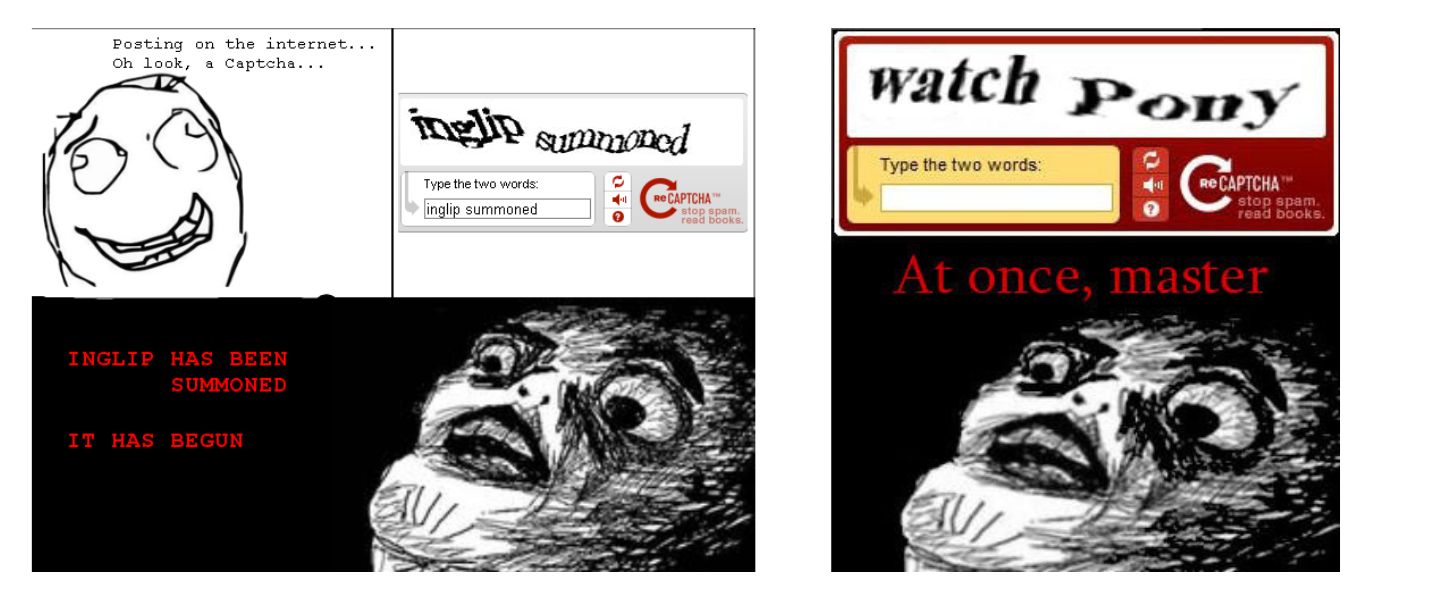
I won’t delve further into the complexities of Inglip here, but if you’d like to, there’s plenty of information out there.
Personally, I think the “select all the squares” format is the true star of the CAPTCHA meme game. Technically, it’s still an unconfirmed meme, but I have faith. This meme style has a few variations — stressful choices, responses to nonsensical requests, and made-up photo grids.
My personal favorite is the stress sweats guy. The Sweating Jordan Peele meme is paired with a photo grid that shows the requested object (traffic light, bicycle, etc.) bleeding ever-so-slightly into another square, making you question whether it qualifies as “containing” the object.
For example, a prompt for traffic lights where the tiniest tip of a light crosses into an otherwise empty square. Or a request for squares containing a bicycle with the edge of a tire barely crossing into another square.

Another reCAPTCHA meme format highlights that computers aren’t always perfect. Responses to prompts that are impossible or difficult to solve result in memes like the one below, where the Blinking White Guy meme reacts to a prompt for fire hydrants in a photo that doesn’t contain any.

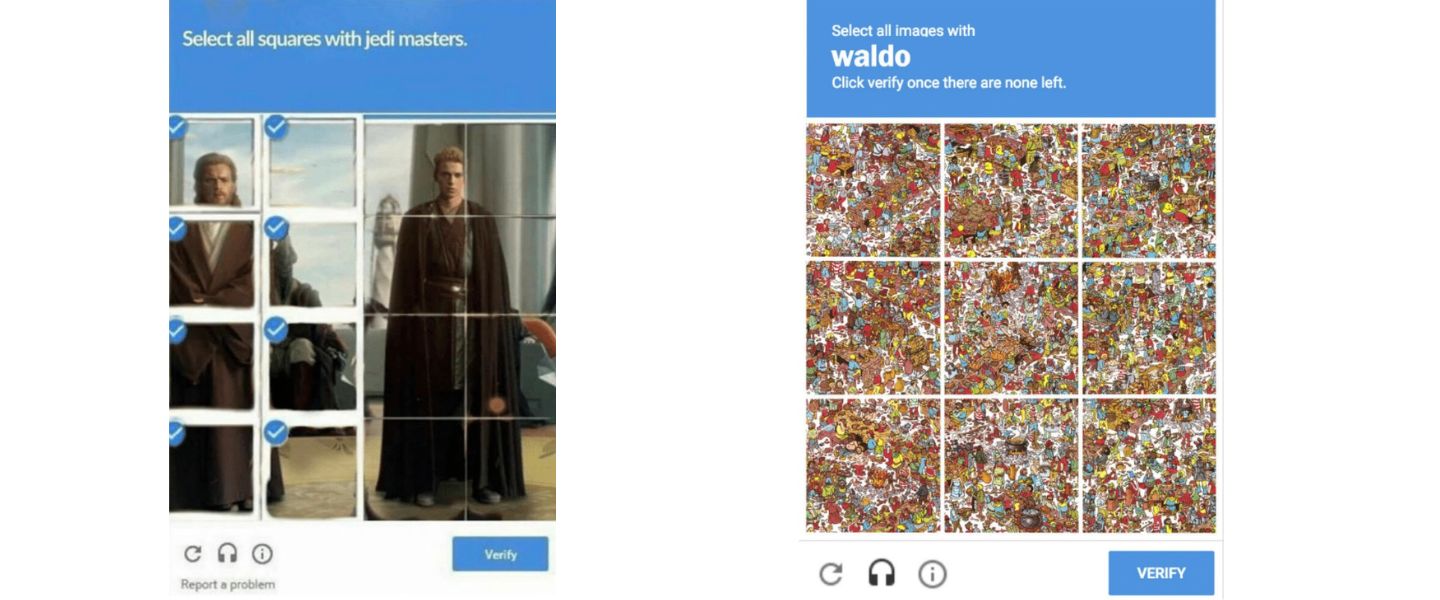
And of course there are the completely manufactured photo grids. For this version, meme creators generally insult someone (e.g., a Jedi master prompt that leaves out Anakin) or exaggerate the difficulty of reCAPTCHAs (e.g., a Where’s Waldo prompt).
What will reCAPTCHAs do next?
Now that these bot blockers have preserved over a century’s worth of NYT archives and millions of books, what’s left for them to accomplish?
Seeing as Google reCAPTCHA is the go-to solution, Google will probably continue to use them for their own purposes, like training machine learning and analyzing user behavior.
If that bums you out, maybe knowing what happened to the original CAPTCHA creator will help. Remember Luis von Ahn from Carnegie Mellon University? He took what he learned about serving two goals at once with him and co-founded the language learning app, Duolingo.
Luis was passionate about offering a free option, so in the early years (before he received more funding) he sustained the business by using aspects of the app as a translation service — much like the early CAPTCHA and transcription model.
And let’s not forget about the memes. No matter how this technology is used, no one can stop the people of the internet from creating and enjoying reCAPTCHA memes.



















Get started for free
Create custom, scalable websites — without writing code. Start building in Webflow.

























