



With millions of sites hosted on our platform, gaining a deeper understanding of design trends and user preferences across such a vast and visually diverse ecosystem is both a challenge and an exciting opportunity.
To address this at scale, we developed an in-house AI-powered system based on open-source technologies that analyzes and interprets visual design elements, uncovering actionable insights to better inform our platform offerings and future innovation.
Why in-house and open source?
One might wonder why we decided to rely on open source tools to build this system from the ground up:
Privacy and compliance
We opted for an in-house approach to ensure that we fully comply with Webflow’s Terms of Service and privacy guidelines and that we maintain strict control over how and where the data is processed.
Cost efficiency
As of this writing, using third-party vendors like OpenAI or Anthropic to process visual content would have been prohibitively expensive. By leveraging open-source tools and hosting the infrastructure ourselves, we achieved a remarkable 17x reduction in cost, making large-scale analysis both feasible and highly efficient.
Full control and customization
Developing the system internally gave us complete control over the pipeline, enabling us to seamlessly integrate with our infrastructure and tailor the system to Webflow’s unique requirements.
Understanding the technical components
To bring this in-house solution to life, we designed a robust system that combines state-of-the-art AI models with scalable infrastructure, capable of analyzing websites efficiently. Here’s how the pieces come together:
Vision-language model
Model choice
At the heart of our entire system is the vision-language model, tasked with analyzing the visual design and content of websites to extract meaningful insights.
For this critical role, we selected Qwen2-VL-7B-Instruct, an Apache 2.0-licensed open-source model, which, as of November 2024, was not only one of the most advanced models available, balancing cutting-edge performance with scalability and cost efficiency, but also outperformed GPT-4 Vision Mini on multiple benchmarks.
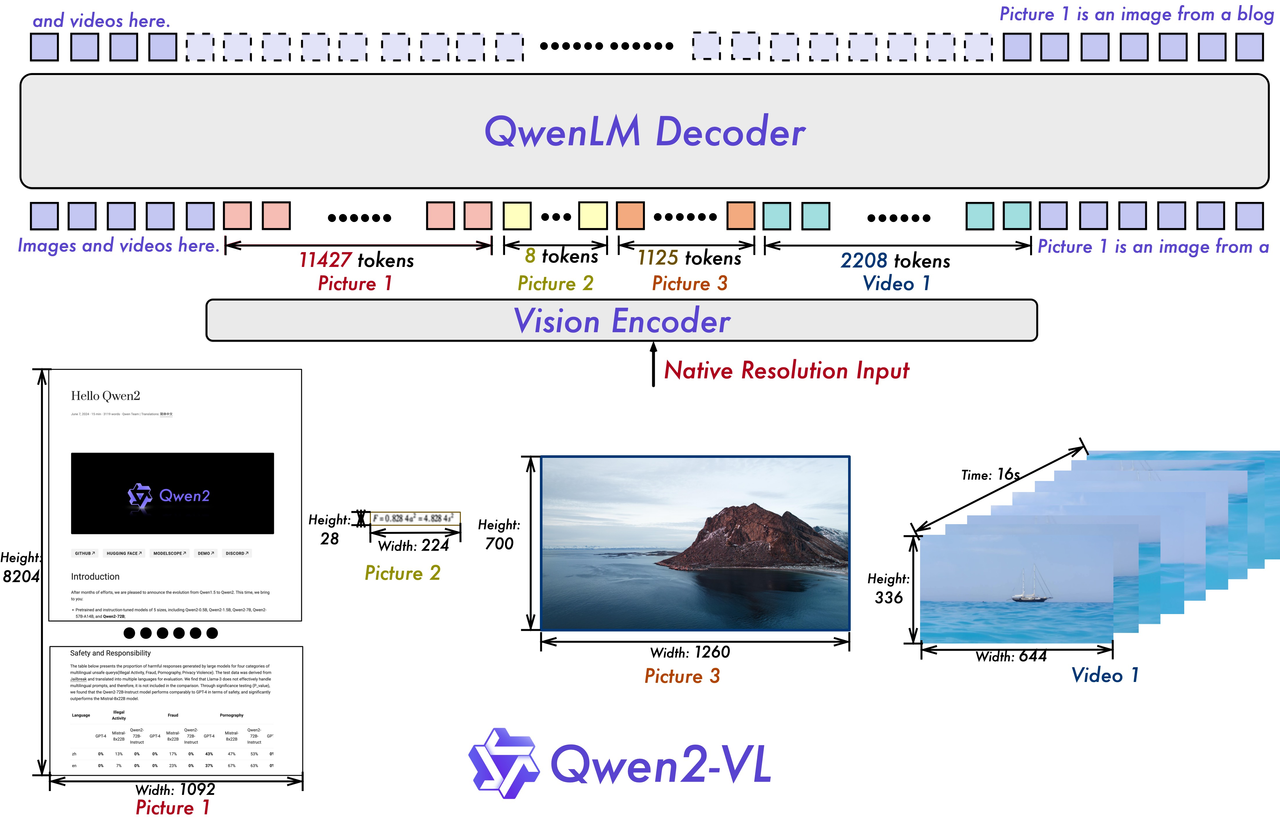
Moreover, with 7 billion parameters, it strikes an ideal balance between capability and resource efficiency, making it suitable for large-scale applications like ours.
Model characteristics
Vision transformer (ViT) integration
The model incorporates a Vision Transformer (ViT) as its vision encoder and uses SwiGLU activation functions and RMSNorm layers. These enhancements align the ViT with the structure of the Qwen2.5 language model, which improves inference speed.
Dynamic resolution handling
Qwen2-VL-7B-Instruct supports dynamic resolution, enabling it to process images of various sizes and aspect ratios without compromising performance. This flexibility is essential for analyzing diverse website designs.
Multilingual processing
Webflow powers websites from all over the world, supporting businesses, freelancers, and enterprises across diverse regions and languages. With our Localization product, users can seamlessly translate their sites into multiple languages, ensuring accessibility for different audiences. To align with this global reach, our Site Analyzer needed to handle multilingual text analysis without compromising accuracy.
Instruction-tuning
The instruction-tuned variant of Qwen2-VL-7B is specifically designed to handle tasks that require understanding and generating responses based on given instructions. This tuning makes it adept at producing consistent and structured outputs, such as JSON-formatted data, which is crucial to save the information in our database.
Scalable text generation with vLLM
To power the text generation, we leveraged vLLM, a high-performance library optimized for efficient, scalable, and flexible LLM inference. This library was an ideal fit for our system due to its advanced features:
- PagedAttention Mechanism: vLLM optimizes memory usage by reducing fragmentation, resulting in higher throughput and better resource efficiency.
- Multi-GPU Parallel Processing: It supports tensor parallelization, enabling workloads to be distributed across GPUs, significantly reducing processing time.
- Flexibility for Multi-Modal Inputs: It can seamlessly handle both text and image data, aligning perfectly with our need for vision-language processing.
Deployment with SkyPilot on AWS
To efficiently manage and scale our AI workloads, we utilized SkyPilot, an open-source framework that seamlessly integrates with AWS to orchestrate and balance workloads across multiple GPUs. SkyPilot dynamically distributes tasks, minimizes idle time, and queues requests when GPUs are busy, ensuring optimal resource utilization.
For this specific system, we deployed an 8-GPU cluster with NVIDIA L40 GPUs, enabling parallel processing of multiple vLLM instances.
Integrating the components
Here’s how we integrated all the components to create a seamless site analysis pipeline:
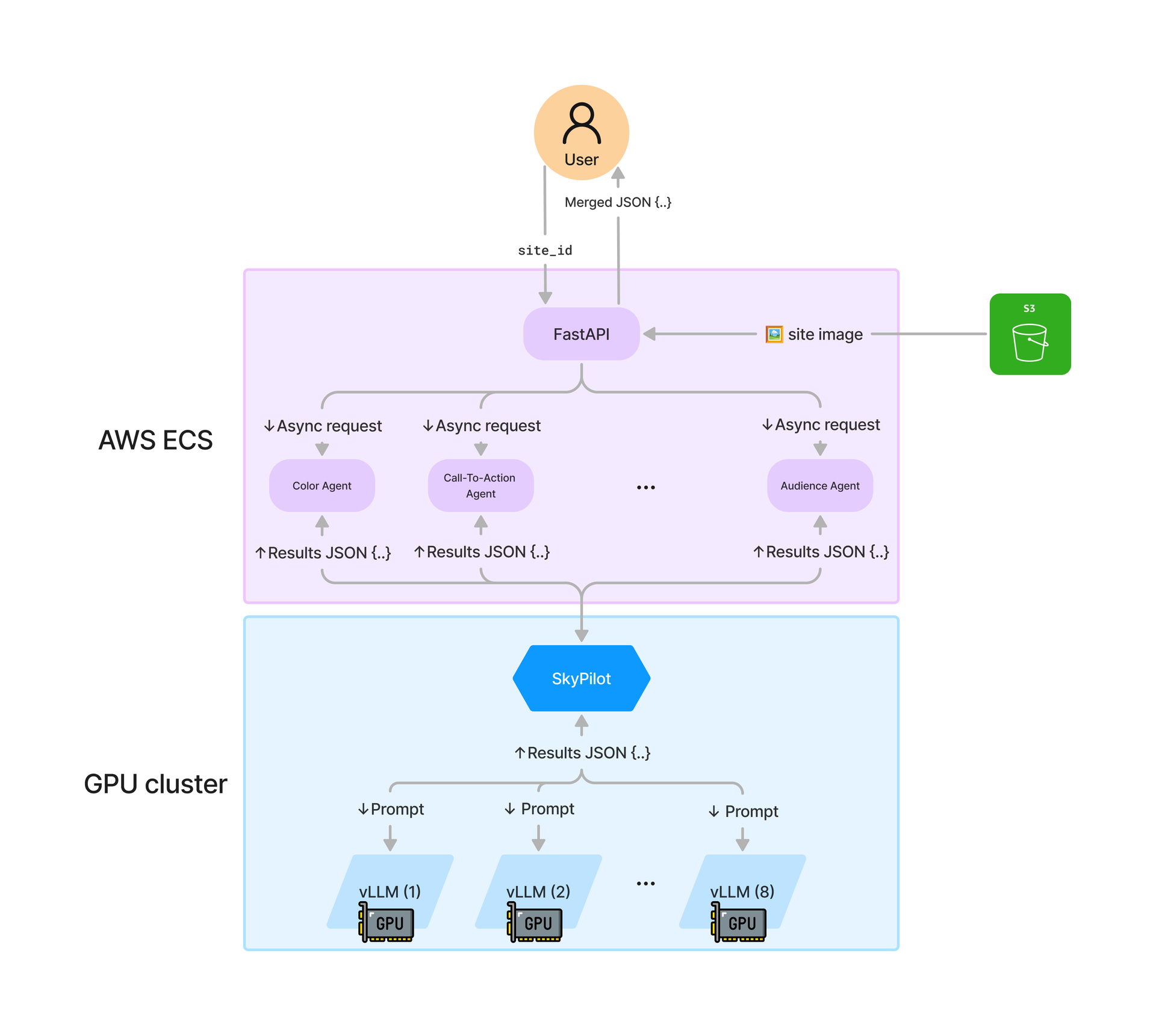
API endpoint and input handling
We set up a Dockerized FastAPI application deployed on Amazon Elastic Container Service (ECS), through which the analysis gets initiated by making an API call using the unique identifier of the site (site_id) as argument.
Asynchronous insight agents
Upon receiving site_id, the FastAPI app fetches the visual components of the site from our database and orchestrates the analysis by dispatching multiple specialized agents, each responsible for a distinct aspect of the site’s design and functionality. For example, separate agents handle Color Analysis, Audience Targeting, Call-To-Actions analysis, and other key insights. These agents operate asynchronously, enabling parallel processing and significantly reducing the overall response time.
Request routing with SkyPilot
Each insight agent sends a GET request to SkyPilot, our chosen orchestration layer, which efficiently manages load balancing across our GPU-powered instances. SkyPilot dynamically routes each request to the appropriate GPU instance within our 8-GPU NVIDIA L40 cluster, leveraging its ability to minimize idle time and maximize resource utilization. This ensures that each agent receives the necessary computational power to perform complex vision-language tasks without bottlenecks.
Vision-language model processing
Once routed, the Qwen2-VL-7B-Instruct model processes the specific piece of information required by the agent.
Aggregation and response construction
As each agent completes its analysis, the results are sent back to the FastAPI application, which will await all incoming insights. Once all agents have returned their findings, the FastAPI app aggregates the data, merging the individual insights into a unified response structure. This aggregated data is then sent back to the user, providing a holistic view of the site’s design and performance metrics.
Structured output format
To ensure consistency and reliability across all analysis agents, we enforce a structured JSON format for every output. Each agent — whether analyzing color schemes, CTAs, or audience targeting — returns data in a standardized schema. This structured approach makes it easy to store, query, and aggregate insights at scale.
Here’s an example of a “mock” website we created to demonstrate the power of our AI site analyzer:
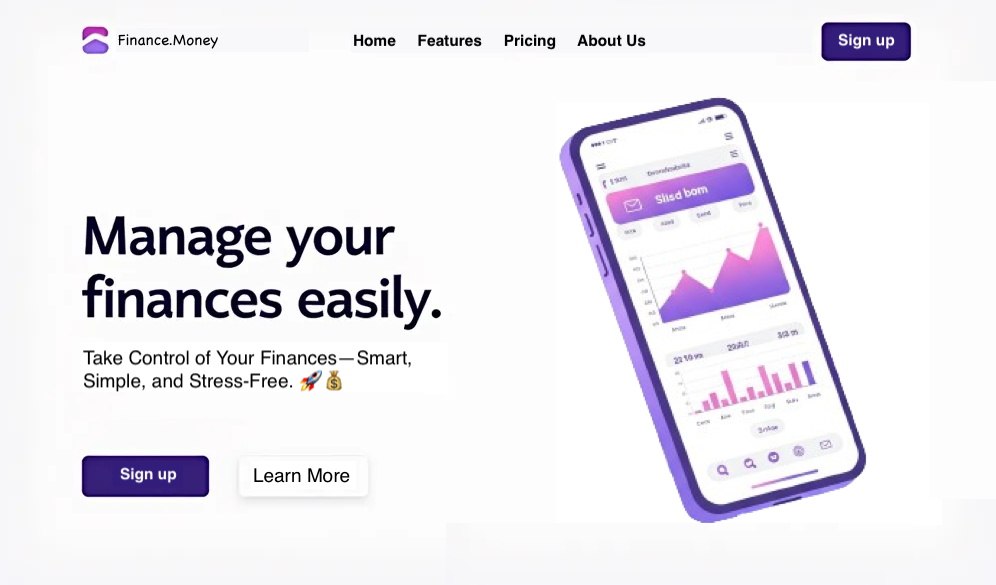
The system provided the corresponding JSON output:
{
"site_id": "621f-f7af-0429-2620-3zec",
"categories": ["banking & investing", "finance & accounting"],
"audience_targeting": {
"audiences": ["Tech-savvy individuals", "Budget-conscious consumers"],
"explanations": [
"The app targets users who are both budget-conscious and tech-savvy.",
"It offers a user-friendly mobile interface to manage finances."
]
},
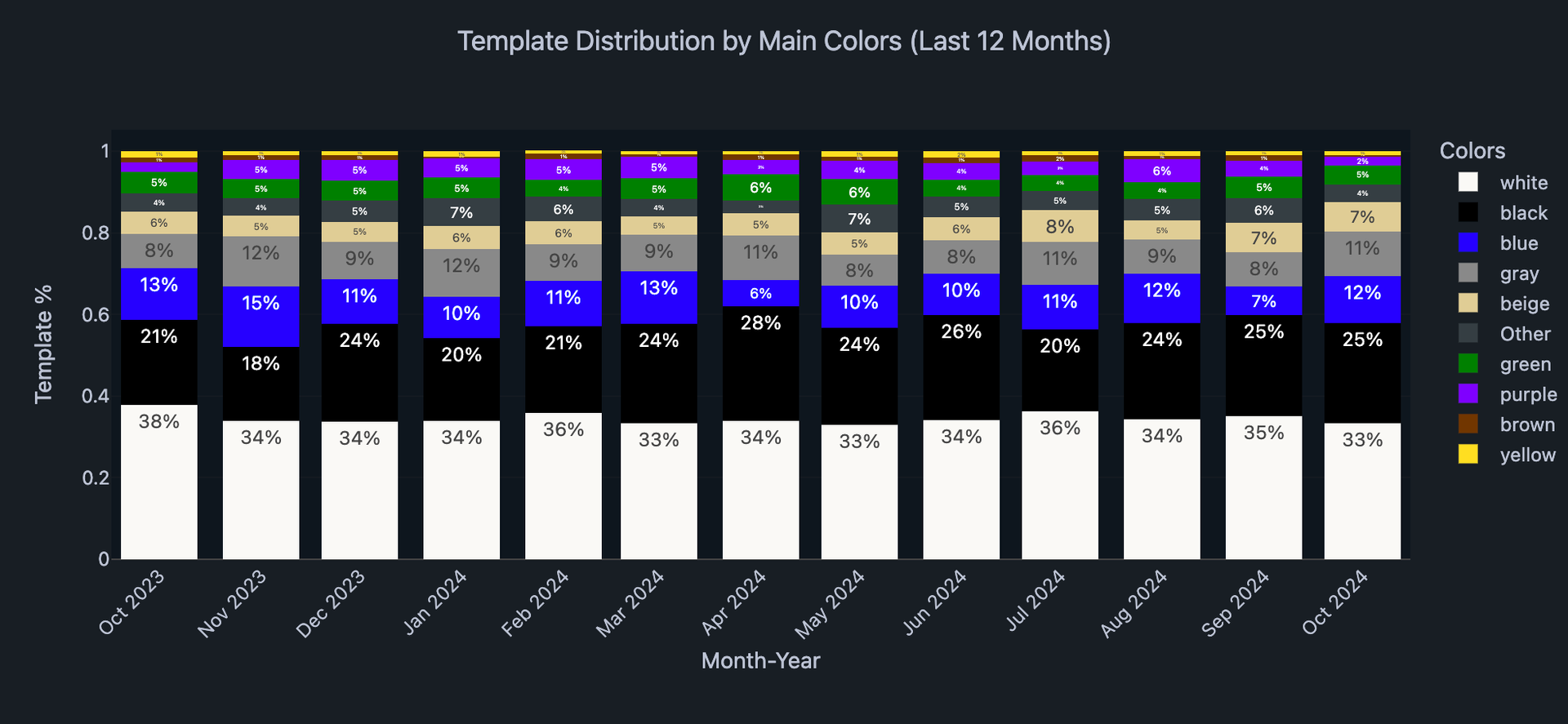
"color_analysis": {
"elements": [
{
"color_name": "White",
"category": "Background",
"emotions": ["Clean", "Minimalistic"]
},
{
"color_name": "Purple",
"category": "Accent",
"emotions": ["Innovative", "Bold"]
}
]
},
"languages": {
"detected_languages": ["English"],
"explanations": "The website only uses English text."
},
...
}


















How we optimized AI inference for large-scale website analysis
Building a scalable AI-powered Site Analyzer wasn’t just about choosing the right model — it required extensive engineering work to ensure fast, efficient, and reliable inference across thousands of requests. This section covers the optimization techniques we implemented for Qwen2-VL-7B-Instruct, vLLM, and FastAPI to make large-scale website analysis possible.
Handling KV caching issues in vLLM
One of the biggest challenges we faced with vLLM was its aggressive key-value (KV) caching mechanism. vLLM is designed to optimize inference by reusing cached sequences when the input prompt is similar across multiple requests.
However, in our case, this led to unexpected inference repetition — where completely different websites produced the same output because the beginning of the prompt was too similar. To address this, we introduced dynamic placeholders in the system prompt, ensuring that each request had minor variations in wording while maintaining its original intent.
Therefore, at inference time, we dynamically replace placeholders with randomly selected synonyms; this introduces slight variations and prevents excessive KV caching.
import random
# System prompt with placeholders
system_prompt = """
{synonym_for_you_are} a vision-language {synonym_for_ai} for Webflow.
Your task is to analyze website screenshots and extract {synonym_for_relevant} {synonym_for_insights}.
"""
# List of synonyms
synonyms_for_you_are = ["You're", "You are", "You act as", "Imagine you are"]
synonyms_for_ai = ["AI assistant", "language model", "intelligent agent"]
synonyms_for_relevant = ["valuable", "useful", "key"]
synonyms_for_insights = ["findings", "analysis", "observations"]
# Function to generate prompts
def generate_prompt(system_prompt: str) -> str:
"""
Replaces placeholders with randomly synonyms to introduce slight variations
and prevent excessive KV caching in vLLM inference.
Args:
system_prompt (str): A template string containing placeholders.
Returns:
str: The formatted system prompt with randomized synonyms.
"""
return system_prompt.format(
synonym_for_you_are=random.choice(synonyms_for_you_are),
synonym_for_ai=random.choice(synonyms_for_ai),
synonym_for_relevant=random.choice(synonyms_for_relevant),
synonym_for_insights=random.choice(synonyms_for_insights),
)
print(generate_prompt(system_prompt))Running vLLM as a separate process for better performance
During development, we experimented with directly integrating vLLM within FastAPI but found that running vLLM as an independent server using the OpenAI-compatible API mode, allowing FastAPI to interact with vLLM over HTTP, led to better performance and stability.
# Start vLLM as an OpenAI-compatible API server
python -u -m vllm.entrypoints.openai.api_server \
--host $HOST \
--port $VISION_LANGUAGE_PORT \
--model $VISION_LANGUAGE_MODEL_ID \
--max-model-len $VISION_LANGUAGE_MAX_MODEL_LEN \
--device $VISION_LANGUAGE_DEVICE \
--dtype $VISION_LANGUAGE_DTYPE \
--load-format safetensors \
--gpu-memory-utilization $VISION_LANGUAGE_GPU_MEMORY_UTILIZATION \
--cpu-offload-gb $VISION_LANGUAGE_CPU_OFFLOAD_GB \
--tensor-parallel-size $VISION_LANGUAGE_TENSOR_PARALLEL_SIZE \
--enforce-eager \
--disable-custom-all-reduce \
--max-num-batched-tokens $VISION_LANGUAGE_MAX_NUM_BATCHED_TOKENS \
--trust-remote-code &
# Start FastAPI separately
uvicorn site_analyzer.main:app --host $APP_HOST --port $APP_PORTHere, we launch it on one port, while FastAPI runs on another port and makes calls to vLLM.
Experimenting with different vLLM configurations
To ensure efficient inference for Qwen2-VL-7B-Instruct, we fine-tuned key vLLM parameters based on our infrastructure and workload. Below is a breakdown of the parameters we used, why they matter, and how they impacted performance.
- max_model_len: 8192
- What it does: Defines the maximum number of tokens that can be processed in a single request
- Why we chose this value: Longer context length allows processing full-page website screenshots without truncation.
- Alternative values:
- 2048 or 4096 → Lower memory usage but insufficient for full-page website text.
- 8192+ → Requires more GPU memory and may degrade inference speed.
- max_new_tokens: 2000
- What it does: Limits the number of tokens the model can generate in response.
- Why we chose this value: Prevents excessively long outputs, keeping responses structured.
- Alternative values:
- 512 → Faster inference but might truncate complex responses.
- 4000+ → More detailed responses but increases latency.
- device: 'cuda'
- What it does: Specifies where to run the model ('cuda' for GPU, 'cpu' for CPU).
- Why we chose this value:
- Running on NVIDIA L40 GPUs ensured fast, parallelized execution.
- CPU inference would be too slow for real-time processing of thousands of sites.
- dtype: 'bfloat16'
- What it does: Defines the precision format for floating-point calculations.
- Why we chose this value:
- Faster inference than float32, while maintaining accuracy.
- More stable than float16, which can underflow in some cases.
- Alternative values:
- 'float32' → Higher precision but slower execution.
- 'float16' → More memory-efficient but may cause numerical instability in certain cases.
- gpu_memory_utilization: 0.8
- What it does: Determines the fraction of GPU memory allocated to vLLM.
- Why we chose this value:
- Keeps memory usage below 100% to avoid OOM (Out of Memory) errors.
- Leaves room for system processes and SkyPilot orchestration.
- Alternative values:
- 0.6 → Conservatively low, may underutilize GPU power.
- 0.9-1.0 → Risk of memory overflow, leading to crashes under heavy load.
How we plan to use this system
Our current prototype has demonstrated the power of vision language models, giving us a glimpse into how design insights can shape product decisions. And we’re just getting started. We have envisioned lots of ways we can use this visual intelligence in our business. By structuring the model insights in a scalable and consistent format, this technology unlocks a wide range of applications across Webflow:
- Trend analysis – By tracking design trends over time — such as shifts in color preferences, typography usage, and layout structures—we can make data-driven improvements to Webflow’s templates, design recommendations, and AI-assisted tools. Understanding how design evolves helps us anticipate user needs and ensure Webflow stays ahead of industry trends.
- Sales enablement – Today, sales teams often ask whether we host company sites in a specific industry when working to close enterprise deals. With this system, we can instantly surface relevant examples, making those conversations faster and more data-driven.
- Personalized recommendations – For users leveraging Webflow Analyze, we can go beyond standard metrics. If a call-to-action (CTA) button has a 5% conversion rate, we can compare it to similar sites and suggest optimizations — like switching to a pink button if our data shows higher conversion rates for that color. This insight could seamlessly tie into Webflow Optimize, enabling users to A/B test these recommendations and drive better engagement.
By leveraging AI-driven insights at scale, we’re not just helping users build beautiful websites — we’re giving them the data they need to make smarter, high-impact design decisions.
Conclusion
Building this site analyzer exemplifies how Webflow leverages cutting-edge AI and open-source tools to solve complex challenges at scale. By seamlessly integrating vision-language models and scalable infrastructure, we’ve developed a system that empowers us to understand design trends and extract actionable insights. This approach allows us to enhance our platform offerings and drive future innovation effectively.
At Webflow, we’re constantly pushing the boundaries of innovation in machine learning and AI to deliver value to our users. If tackling exciting challenges like these sounds appealing, check out our Careers page — we’d love to have you on board!

We’re hiring!
We’re looking for product and engineering talent to join us on our mission to bring development superpowers to everyone.

























