


Learn how HTTP requests work to build better web applications. This guide covers request structure, methods, and status codes with examples for debugging and optimization.
Every time a page loads, a form submits, or an API call fires, your browser emits a plain-text packet that crosses networks, hits a server, and awaits a structured response called an HTTP request.
Understanding what's inside that request and how it moves through the Domain Name System (DNS), Transmission Control Protocol (TCP), and Transport Layer Security (TLS) lets you catch slow endpoints, design predictable APIs, and maintain fast pages.
Read on to learn about request lines, headers, and body structures, along with HTTP methods, status codes, and debugging workflows. All of these implementation-level details will help you build better APIs, debug network issues, and optimize your web applications.
What is an HTTP request?
An HTTP request is a structured message sent to a server requesting resources or actions. When you type a URL, submit a form, or call an API, your client assembles this request. HTTP operates in the application layer of TCP/IP, using TCP (or QUIC for HTTP/3) as its transport.
These requests power all web interactions. Browsers send GET requests to load HTML, CSS, and JavaScript assets. React applications make POST or PATCH calls to REST or GraphQL API endpoints. Checkout flows transmit sensitive payment details over encrypted HTTPS channels. Features like infinite scrolling and live search depend on frequent HTTP requests to fetch additional content.
HTTP's strength comes from its minimalist design that remains simple, extensible, and stateless. You can add headers, authentication, or caching directives without modifying the core protocol rules. Because each request contains all the information needed for processing, HTTP enables horizontal scaling as servers do not need to maintain session memory between requests.
Effective HTTP usage requires understanding header semantics, method idempotency, and caching directives. While HTTP/1.1 remains common, HTTP/2 improves performance through multiplexed connections, and HTTP/3 reduces latency by replacing TCP with QUIC.
Regardless of version, the fundamental request message structure forms the foundation for all HTTP implementations.
Anatomy of an HTTP request
All HTTP requests contain a request line, headers, and an optional body. Learning this structure thoroughly will help you troubleshoot network issues more effectively than any browser console can display.
The request line comes first, containing the method (GET, POST, etc.), the resource path, and protocol version, separated by spaces, like so: GET /index.html HTTP/1.1. This line ends with CRLF (\r\n), which is the carriage return and line feed sequence the HTTP message format requires.
Headers follow as key-value pairs that carry request metadata. A blank line (another CRLF) marks where headers end. You'll work with these headers constantly:
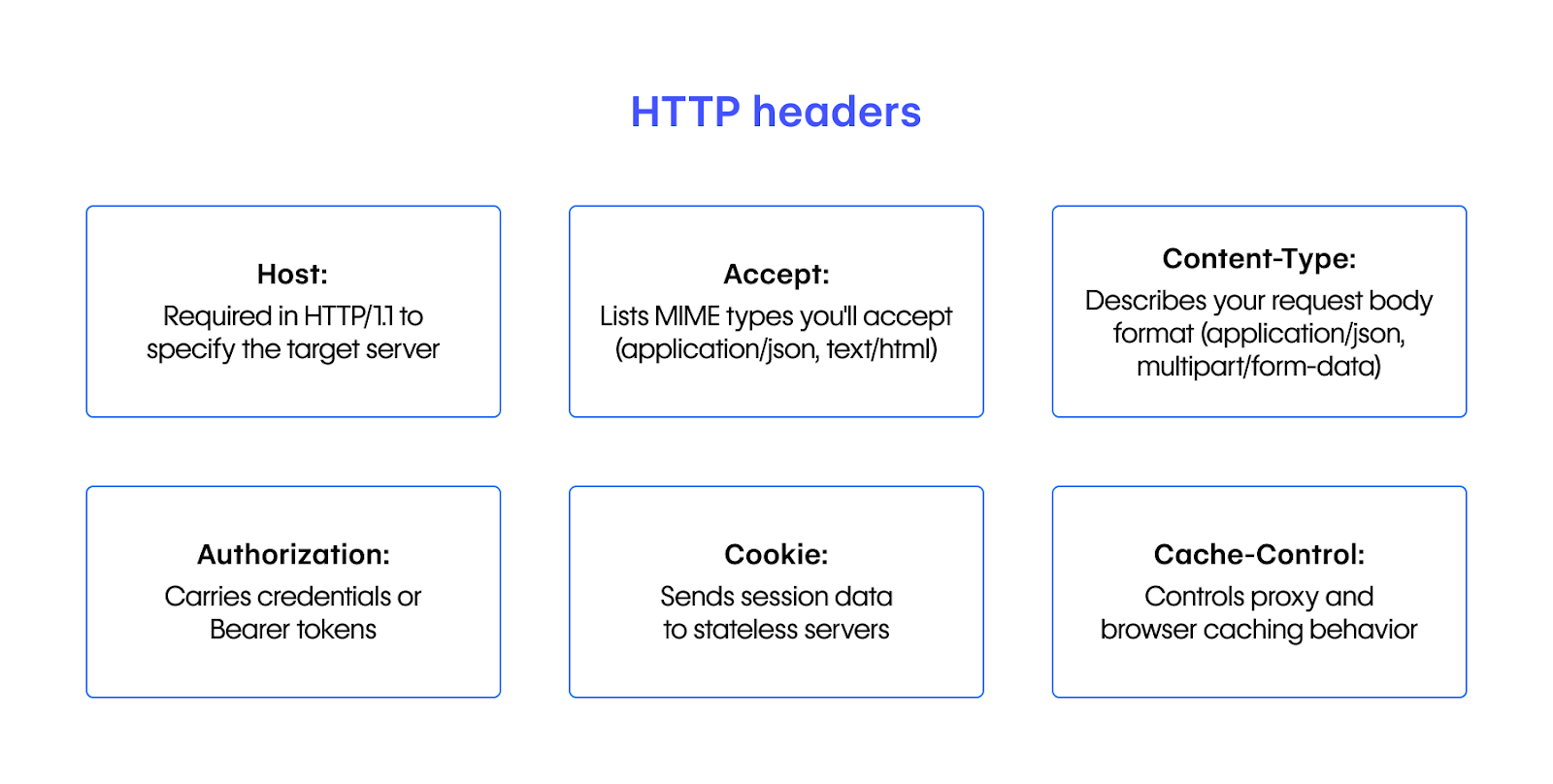
Host: Required in HTTP/1.1 to specify the target serverAccept: Lists MIME types you'll accept (e.g.,application/json, text/html)Content-Type: Describes your request body format (e.g.,application/json,multipart/form-data)Authorization: Carries credentials, most often as Bearer tokens or Basic auth, though other schemes exist.Cookie: Sends identifiers (like session IDs or tokens) so stateless servers can maintain context across requests.Cache-Control: Controls proxy and browser caching behavior
The message body appears last, after the blank line. Methods that modify server state, like POST, PUT, and PATCH, typically include a body with JSON, form data, or files. Safe methods like GET don’t include a body. While DELETE requests can technically include one, most servers ignore it.
Here's a complete request showing all three parts:
POST /api/items HTTP/1.1
Host: example.com
Accept: application/json
Content-Type: application/json
Authorization: Bearer <token>
Content-Length: 48
{
"name": "Keyboard",
"price": 49.99
}
You can visualize HTTP requests with three distinct layers. The request line directs traffic to your specific resource. The headers supply the necessary processing context. The body contains your actual payload data. This straightforward mental framework simplifies both low-level debugging and API design.
How HTTP requests travel
When you type a URL and hit Enter, your HTTP request travels through several network layers before reaching its destination. This journey involves a client sending a request and waiting for a response that carries the status of the operation and the requested content.
Here's a visual representation of how an HTTP request travels:
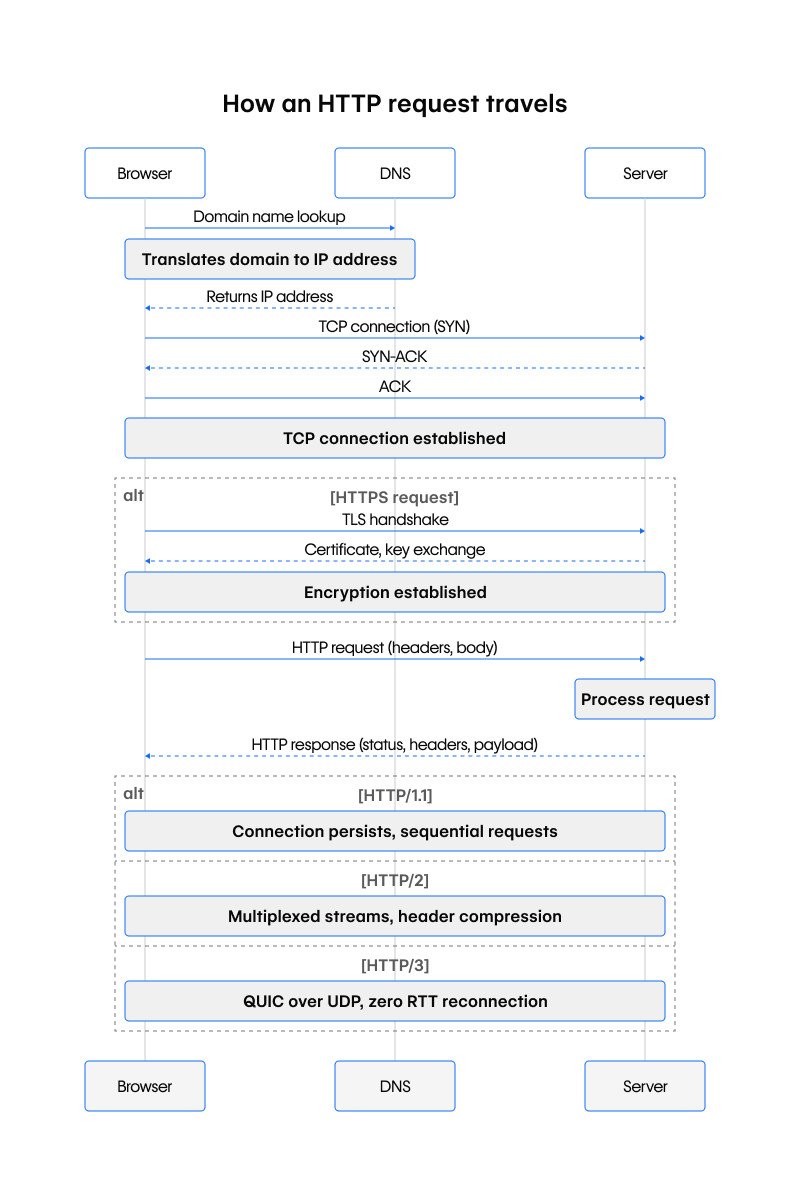
First, your browser needs an IP address. A DNS lookup asks recursive and authoritative name servers to translate the domain to an address the network understands. If nothing is cached locally, these round-trips add the first milliseconds of latency.
With an IP in hand, the browser opens a TCP connection. The familiar three-way handshake (SYN, SYN-ACK, and ACK) establishes a reliable transport channel. When the scheme is https, a TLS handshake immediately follows. During this process, the client and server negotiate ciphers, verify certificates, and derive keys to encrypt every subsequent byte transmitted.
Only now does your browser transmit the actual HTTP message. Headers, including Host, User-Agent, and Accept, travel alongside the request line and a body, if one exists. On the server, a web application might query a database or call downstream services before crafting an HTTP response with a status code, headers, and payload.
HTTP is stateless. Each request is independent, but you often carry context through cookies or Bearer tokens, making the workflow "stateless but not sessionless."
After the response arrives, the underlying connection may persist. HTTP/1.1 made persistent connections the default, so multiple requests could reuse a single connection (previously signaled with Connection: keep-alive in HTTP/1.0). However, each request still waits its turn. HTTP/2 changes this by multiplexing multiple concurrent streams over one connection and compressing header frames, reducing both latency and bandwidth overhead.
The newest evolution, HTTP/3, runs over QUIC on UDP instead of TCP. QUIC combines transport and security handshakes, enabling zero-round-trip re-connections and eliminating head-of-line blocking, so requests continue flowing even when packets are lost.
Understanding this timeline helps you pinpoint where slowdowns occur: DNS misconfiguration, long TLS negotiation, chatty application logic, or the lack of HTTP/2 multiplexing. By mapping performance issues to specific phases, you can make targeted fixes instead of guesswork.


















9 HTTP request methods and which one to pick
Every request you send carries an HTTP method or verb that tells the server what you intend to do with a resource. Choosing the right method clarifies expectations for safety, idempotency, caching, and even security.
The HTTP/1.1 specification defines eight core methods that serve distinct purposes. These include GET, HEAD, POST, PUT, DELETE, OPTIONS, TRACE, and CONNECT. PATCH was added later as an extension method.
Properties marked "safe" or "idempotent" follow HTTP semantics. Safe methods must not mutate server state, while idempotent ones can be repeated with the same result, which can be critical when you implement retries.
When to pick one method over another
You'll often decide between pairs of verbs that look similar at first glance. Here's how to choose the right method for your specific use case:
GETvs.HEAD:GETretrieves the complete resource whileHEADfetches only headers. UseGETwhen you need the actual content. ChooseHEADwhen you need metadata likeContent-Lengthbefore deciding whether to download large files.POSTvs.PUT:POSTcreates resources when the server determines the identifier, whilePUTcreates or replaces at a specific URI you control. UsePOSTwhen creating items in a collection without knowing the final ID (like a new order). ChoosePUTwhen you know exactly where the resource belongs and want to ensure idempotency, so repeating the samePUTwon't create duplicates.PATCHvs.PUT:PUTreplaces an entire resource whilePATCHupdates only specific fields. UsePUTwhen overwriting a complete resource. ChoosePATCHfor partial updates (like changing just a product'sstockfield) to avoid accidentally overwriting unchanged data. Note thatPATCHis not guaranteed to be idempotent. Whether repeatedPATCHrequests produce the same result depends on how the server implements the operation..
Understanding these distinctions helps you design more predictable and maintainable APIs that follow standard HTTP conventions.
5 types of HTTP status codes
Server responses include a three-digit status code summarizing the outcome. This code immediately tells you whether to render content, redirect, show errors, or retry without parsing the entire response body.
HTTP status codes fall into five classes based on their first digit:

- 1xx Informational (100–199) indicates the server received your request and is still processing. These appear mainly during complex uploads like large file transfers.
- 2xx Success (200–299) means the operation succeeded. Common examples include
200 OKforGETrequests and201 Createdafter successful resource creation. - 3xx Redirection (300–399) requires another request to complete the workflow. Examples include
301 Moved Permanently,302 Found, and304 Not Modified, affecting caching and SEO. - 4xx Client error (400–499) indicates client-side issues. Examples include
400 Bad Requestfor malformed payloads,401 Unauthorizedfor missing credentials,403 Forbiddenfor permissions issues,404 Not Foundfor non-existent resources, and429 Too Many Requestsfor rate limiting. - 5xx Server error (500–599) means your request was valid, but server processing failed. Common codes include
500 Internal Server Error,502 Bad Gateway, and503 Service Unavailable.
Handle these consistently for resilient applications.
- Treat 2xx as success, update routing for 3xx, and monitor 4xx and 5xx in dashboards.
- Implement retry logic for
502/503, back off on429, and fail immediately on400. - Use circuit breakers that open after consecutive 5xx responses and gradually retest.
This turns network traffic into predictable, fault-tolerant behavior.
How to monitor & debug HTTP requests
Discover performance bottlenecks by observing actual HTTP traffic. Use these practical tools:
- Browser DevTools: Network panel shows request waterfalls with DNS, TCP, TLS phases. Filter XHR calls and export HAR files for sharing.
- Command-line tools:
curl -vshows raw requests and responses.httpieoffers formatted output.tcpdumpandngrepcapture packet data. - API clients: Postman and Insomnia enable repeatable tests with collections and environments. GoReplay captures traffic for regression testing.
- Production monitoring: OpenTelemetry with Datadog or Jaeger visualizes latency and error rates. Log request timestamps to track performance trends.
Webflow Cloud provides these metrics automatically with request counts, latency, and status codes.
For precise measurements, use cURL timing:
curl -o /dev/null -s -w "@curl-format.txt" \
-H "Accept: application/json" \
https://api.example.com/v1/users/42A custom format file tracks time_namelookup, time_connect, and time_starttransfer values to pinpoint delays in DNS, connection, or processing.
Using HTTP Requests to Build Better APIs
Every HTTP interaction follows the same straightforward structure: a request line stating method, path, and protocol version, headers that carry context, and an optional body with data. When you understand how these three pieces work together, you can read any raw request and immediately see what the client wants, what metadata tags along, and whether there's a payload.
This knowledge pays off in your daily work. You'll trace bugs faster in the browser's Network panel, write precise curl commands during API development, and spot performance bottlenecks like wasted round-trips or oversized payloads. The core semantics — methods, status codes, and the stateless request/response cycle — stay consistent from HTTP/1.1 through HTTP/3, so these skills will serve you well as transport layers evolve.
Next time you're debugging a tricky API issue, inspect the raw request, adjust a header, measure what changes, and apply what you learn to your next project.
HTTP request frequently asked questions
What's the difference between HTTP and HTTPS?
HTTP sends data as plain text, while HTTPS encrypts the application data sent over TCP using TLS, protecting it in transit.. The TLS handshake encrypts data in transit and authenticates the server with a certificate, preventing eavesdropping that plain-text HTTP
How do cookies relate to HTTP requests?
HTTP is stateless, so cookies in the Cookie header carry session IDs or tokens between requests. Servers return Set-Cookie in responses to persist user context without embedding state in the protocol itself.
What are the size limits for HTTP requests?
The HTTP specification sets no hard limit, but browsers, proxies, and servers impose practical constraints: headers typically cap at 8–16 KB, bodies at tens of megabytes. Check your web server config, Nginx's client_max_body_size, for example, before assuming large payloads will arrive intact.
How do I troubleshoot CORS errors in HTTP requests?
Browsers block cross-origin requests unless the server responds with Access-Control-Allow-Origin (and sometimes Allow-Credentials). Use DevTools to inspect the automatic OPTIONS preflight request, then adjust server-side headers so your origin, methods, and headers are explicitly allowed. MDN's HTTP guide covers every header involved.
What's the difference between query parameters and form data?
Query parameters live in the URL (/products?sort=asc&page=2) and suit idempotent GET or HEAD requests. Form data travels in the message body, often as application/x-www-form-urlencoded or multipart/form-data, and works for POST, PUT, or PATCH when sending user input or files.
How do HTTP/2 and HTTP/3 change request handling?
HTTP/2 multiplexes multiple streams over one TCP connection, eliminating HTTP/1.1's "one-request-at-a-time" head-of-line blocking. HTTP/3 replaces TCP with QUIC over UDP, combining multiplexing with faster, packet-loss-resistant handshakes. Both reduce latency without changing the request format.
Can I cancel an HTTP request after it's sent?
You can close the underlying socket or, in modern browsers, abort a fetch with AbortController. The server may still finish processing, but your application thread regains control and can ignore the eventual response.
How do I handle authentication in HTTP requests?
Attach credentials in the Authorization header, like Bearer <token> for JWTs, Basic <base64> for simple user/pass, or rely on session cookies set after login. Always use HTTPS so tokens and passwords stay encrypted in transit.

Build websites that get results.
Build visually, publish instantly, and scale safely and quickly — without writing a line of code. All with Webflow's website experience platform.